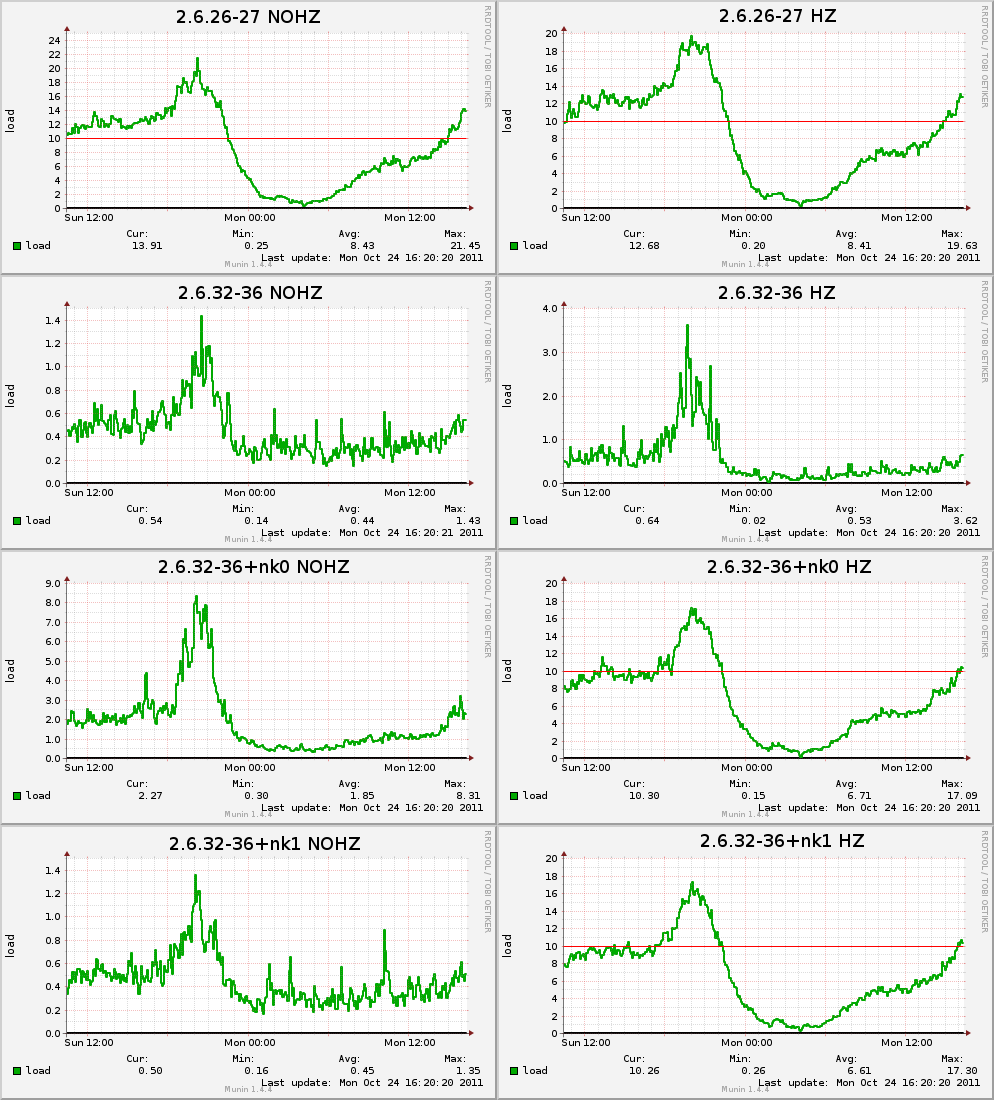
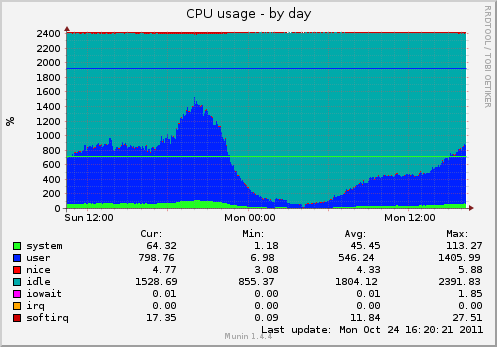
Hello again. I've finally managed to get back to this bug and do some more testing. There are two upstream patches that are fixing the load calculation bug: 74f5187ac8: sched: Cure load average vs NO_HZ woes 0f004f5a69: sched: Cure more NO_HZ load average woes This time I'm using the 2.6.32-36 kernel version. I have prepared one image with only the first patch applied (+nk0) and another with both of them (+nk1). The standard Debian kernels (2.6.26-27 and 2.6.32-36) were also taken into account. Each version was also complied with CONFIG_NO_HZ=n to see if this makes any difference. A comment in 0f004f5a69 states that CONFIG_NO_HZ should produce the same load. The results are quite confusing: kernel load average 2.6.26-27 (NOHZ): 12.86 12.91 13.08 2.6.26-27 (HZ): 14.35 13.56 13.04 2.6.32-36 (NOHZ): 0.42 0.54 0.50 2.6.32-36 (HZ): 0.74 0.89 0.79 2.6.32-36+nk0 (NOHZ): 2.62 2.48 2.37 2.6.32-36+nk0 (HZ): 9.10 9.78 10.03 2.6.32-36+nk1 (NOHZ): 0.62 0.64 0.58 2.6.32-36+nk1 (HZ): 10.64 10.96 10.68 Running vmstat 60 4 produces almost the same output on all hosts: procs -----------memory---------- ---swap-- -----io---- -system------cpu---- r b swpd free buff cache si so bi bo in cs us sy id wa 16 0 0 6719880 0 2091432 0 0 0 0 0 1 22 2 76 0 9 0 0 6665312 0 2091436 0 0 0 0 14685 51017 36 4 60 0 11 0 0 6711220 0 2091428 0 0 0 0 14557 50844 36 4 61 0 15 0 0 6719872 0 2091432 0 0 0 0 15073 52578 38 4 58 0 15 0 0 6716792 0 2091432 0 0 0 0 14822 49843 36 4 60 0 I've attached a comparison of all load charts and one CPU chart. The CPU usage is very similar on all hosts and tiny variations shouldn't matter in the long run. Especially since load values are so different. I've also attached a modified patch 74f5187ac8 (just a minor correction) that can be applied cleanly to Debian's 2.6.32 sources. The bug seems to only appear if the cores go into idle. When I run a process that hogs a given number of cores the load is increased by a corresponding amount. This happens on all kernels that I've tested. The hosts are diskless (root on a NFS share) PHP workers that have the same hardware (24 CPU cores) and do the same kind of work. I getting similar results on disk based systems as well. Conclusions: - load values are quite similar on HZ kernels with exception of 2.6.32-36 - load is suspiciously low on 2.6.32 NOHZ kernels - patch 74f5187ac8 seems to a step in the right direction - applying patch 0f004f5a69 on top of first one produces the similar results as an unpatched kernel Can somebody verify that the patches behave the same way? Should the patches be applied to kernels from 2.6.32 line? Is there something I'm missing? I'm running out of ideas and would appreciate any hints. -- Lesław Kopeć
Attachment:
load-comparison.png
Description: PNG image
Attachment:
cpu.png
Description: PNG image
Patch is based on an upstream commit. Only formatting has been changed in
order to allow patching without any offsets. The original patch header:
commit 74f5187ac873042f502227701ed1727e7c5fbfa9
Author: Peter Zijlstra <a.p.zijlstra@chello.nl>
Date: Thu Apr 22 21:50:19 2010 +0200
sched: Cure load average vs NO_HZ woes
Chase reported that due to us decrementing calc_load_task prematurely
(before the next LOAD_FREQ sample), the load average could be scewed
by as much as the number of CPUs in the machine.
This patch, based on Chase's patch, cures the problem by keeping the
delta of the CPU going into NO_HZ idle separately and folding that in
on the next LOAD_FREQ update.
This restores the balance and we get strict LOAD_FREQ period samples.
Signed-off-by: Peter Zijlstra <a.p.zijlstra@chello.nl>
Acked-by: Chase Douglas <chase.douglas@canonical.com>
LKML-Reference: <1271934490.1776.343.camel@laptop>
Signed-off-by: Ingo Molnar <mingo@elte.hu>
diff --git a/kernel/sched.c b/kernel/sched.c
index 82078b6..7ca3ba6 100644
--- a/kernel/sched.c
+++ b/kernel/sched.c
@@ -1796,7 +1796,7 @@ static void cfs_rq_set_shares(struct cfs_rq *cfs_rq, unsigned long shares)
}
#endif
-static void calc_load_account_active(struct rq *this_rq);
+static void calc_load_account_idle(struct rq *this_rq);
static void update_sysctl(void);
static inline void __set_task_cpu(struct task_struct *p, unsigned int cpu)
@@ -3126,6 +3126,61 @@ static unsigned long calc_load_update;
unsigned long avenrun[3];
EXPORT_SYMBOL(avenrun);
+static long calc_load_fold_active(struct rq *this_rq)
+{
+ long nr_active, delta = 0;
+
+ nr_active = this_rq->nr_running;
+ nr_active += (long) this_rq->nr_uninterruptible;
+
+ if (nr_active != this_rq->calc_load_active) {
+ delta = nr_active - this_rq->calc_load_active;
+ this_rq->calc_load_active = nr_active;
+ }
+
+ return delta;
+}
+
+#ifdef CONFIG_NO_HZ
+/*
+ * For NO_HZ we delay the active fold to the next LOAD_FREQ update.
+ *
+ * When making the ILB scale, we should try to pull this in as well.
+ */
+static atomic_long_t calc_load_tasks_idle;
+
+static void calc_load_account_idle(struct rq *this_rq)
+{
+ long delta;
+
+ delta = calc_load_fold_active(this_rq);
+ if (delta)
+ atomic_long_add(delta, &calc_load_tasks_idle);
+}
+
+static long calc_load_fold_idle(void)
+{
+ long delta = 0;
+
+ /*
+ * Its got a race, we don't care...
+ */
+ if (atomic_long_read(&calc_load_tasks_idle))
+ delta = atomic_long_xchg(&calc_load_tasks_idle, 0);
+
+ return delta;
+}
+#else
+static void calc_load_account_idle(struct rq *this_rq)
+{
+}
+
+static inline long calc_load_fold_idle(void)
+{
+ return 0;
+}
+#endif
+
/**
* get_avenrun - get the load average array
* @loads: pointer to dest load array
@@ -3172,20 +3227,22 @@ void calc_global_load(void)
}
/*
- * Either called from update_cpu_load() or from a cpu going idle
+ * Called from update_cpu_load() to periodically update this CPU's
+ * active count.
*/
static void calc_load_account_active(struct rq *this_rq)
{
- long nr_active, delta;
+ long delta;
- nr_active = this_rq->nr_running;
- nr_active += (long) this_rq->nr_uninterruptible;
+ if (time_before(jiffies, this_rq->calc_load_update))
+ return;
- if (nr_active != this_rq->calc_load_active) {
- delta = nr_active - this_rq->calc_load_active;
- this_rq->calc_load_active = nr_active;
+ delta = calc_load_fold_active(this_rq);
+ delta += calc_load_fold_idle();
+ if (delta)
atomic_long_add(delta, &calc_load_tasks);
- }
+
+ this_rq->calc_load_update += LOAD_FREQ;
}
/*
@@ -3217,10 +3274,7 @@ static void update_cpu_load(struct rq *this_rq)
this_rq->cpu_load[i] = (old_load*(scale-1) + new_load) >> i;
}
- if (time_after_eq(jiffies, this_rq->calc_load_update)) {
- this_rq->calc_load_update += LOAD_FREQ;
- calc_load_account_active(this_rq);
- }
+ calc_load_account_active(this_rq);
sched_avg_update(this_rq);
}
diff --git a/kernel/sched_idletask.c b/kernel/sched_idletask.c
index 93ad2e7..59fa327 100644
--- a/kernel/sched_idletask.c
+++ b/kernel/sched_idletask.c
@@ -23,8 +23,7 @@ static void check_preempt_curr_idle(struct rq *rq, struct task_struct *p, int fl
static struct task_struct *pick_next_task_idle(struct rq *rq)
{
schedstat_inc(rq, sched_goidle);
- /* adjust the active tasks as we might go into a long sleep */
- calc_load_account_active(rq);
+ calc_load_account_idle(rq);
return rq->idle;
}
Attachment:
signature.asc
Description: OpenPGP digital signature
{kind=link}
{kind=link}